For the past couple of years we've been thinking that Genealogy and Web 2.0 were made for each other. Here's an interesting post on the O-Reilly Radar blog about genealogy and Web 2.0.
A colleague brought the effectiveui (www.effectiveui.com) site to my attention. There are some really interesting concepts in their UI that we hope to play with as we start making our push toward a more interesting timeline.
Thursday, December 21, 2006
Friday, December 15, 2006
Timelines
Timelines can be an interesting way to help people understand their genealogy. In the past year I've come across several interesting efforts to build community sites which use a timeline metaphor. Dandelife.com and OurStory.com are two interesting examples. These sites are both focused on building timelines surrounding stories and events happening today and in the very recent past (from a user's own memories). BBC has also done some interesting timelines. Two that I think are extremely interesting from a design perspective are Timeline: Persecution and Genocide Under the Nazis 1933 - 1945 and Kings and Queens Through Time.
One of the focus areas for some prototyping we plan to do in the near future is an effort to allow users to explore timelines of their ancestors that combine a richness of data into an easy to understand format. This is really hard to do. To give you an idea, here is the type of content we'd like to pull together automatically for any random ancestor a user would like to learn about.
What would you like to see in a timeline like this?
Have you seen any interesting timelines that would be worth looking at before we start?
One of the focus areas for some prototyping we plan to do in the near future is an effort to allow users to explore timelines of their ancestors that combine a richness of data into an easy to understand format. This is really hard to do. To give you an idea, here is the type of content we'd like to pull together automatically for any random ancestor a user would like to learn about.
- Genealogical events and associated records for an individual
- Genealogical events and associated records for an individual's family (parents, siblings, spouse, children)
- Modern day and historic maps showing the geographic locations of these events (think Google Earth or Google Maps)
- Historical events that would have impacted people in that place and time
- Historical events that might not have impacted the person but which have impacted their ancestors
- Historical texture (fashion, sports, transportation, entertainment, etc.) throughout the ancestor's life
What would you like to see in a timeline like this?
Have you seen any interesting timelines that would be worth looking at before we start?
Friday, November 17, 2006
Large Format Printing
I've been thinking recently about how much more context the Super Duper Zim Zam Zoom Pedigree Viewer provides (see www.familysearchlabs.org for more details). I never get tired of zooming all the way out to see the whole tree. I do however get tired of not being able to see who anyone is when it is zoomed all of the way out. While the viewer is a definite improvement, I don't think I'd be happy unless I had a monitor 8 feet tall and 8 feet wide. Then I could see my whole family tree and still be able to read the names and details of the individuals.
Well, I don't have an 8' X 8' monitor nor do I see one in my near future. I do however have a 7' X 4' Generation Map from GenerationMaps.com. I love it. If you haven't checked out a Generation Map you should. You will gain a whole new perspective on your family tree.
I took my first Generation Map to a family reunion two summers ago. There were about 50 family members there of which myself and one other do genealogy. I nailed it to a tree in the middle of our campground to see what would happen. Everyone gathered around to see the chart and ask questions. People were captivated by the ability to see so much of our heritage at once.
I also hung it on my kitchen wall for a month or so (much to my wife's dismay). Several times a week I would see the children gathered around it just reading names and looking at where we came from.
Go to www.generationmaps.com and take a look at their working charts to learn more about this unique large format view of your family.
Well, I don't have an 8' X 8' monitor nor do I see one in my near future. I do however have a 7' X 4' Generation Map from GenerationMaps.com. I love it. If you haven't checked out a Generation Map you should. You will gain a whole new perspective on your family tree.
I took my first Generation Map to a family reunion two summers ago. There were about 50 family members there of which myself and one other do genealogy. I nailed it to a tree in the middle of our campground to see what would happen. Everyone gathered around to see the chart and ask questions. People were captivated by the ability to see so much of our heritage at once.
I also hung it on my kitchen wall for a month or so (much to my wife's dismay). Several times a week I would see the children gathered around it just reading names and looking at where we came from.
Go to www.generationmaps.com and take a look at their working charts to learn more about this unique large format view of your family.
Monday, November 06, 2006
Ancestry.com's New Tools
This past September MyFamily, Inc. announced the release of new family tree building tools. I’ve finally found the time to do a really quick (I mean really quick) write up on some of the functionality. It is clearly a step toward making family history accessible to ordinary people. Let me recap the basic experience I recently had as I took another look at the offering.
I put on my ordinary person hat and went to the site. I knew that there was some new tree building tool that would let me attach family artifacts to my tree, I just couldn’t find it. I had to take off my ordinary person hat to find the feature set which is located under the MyAncestry tab. The first thing I tried to do (which is probably not an ordinary person thing) was upload one of my GEDCOM files. For the life of me I couldn’t get the system to accept the file. I kept getting an error saying that it was an invalid GEDCOM file. The ordinary person in me was confused because I didn’t know what the error meant. The non-ordinary person in me was frustrated because I was feeding it the most plain GEDCOM file known to man which I’ve tested on nearly every system known to man and it was failing. This ended up being a good thing as it forced me to put my ordinary person hat back on and go down a different path.
The path I chose (which is more likely to be an ordinary person path) was to create a family tree. I found the wizard-style flow of the creation process to be straightforward and on target with the ordinary person side of me. I did step slightly out of the ordinary person (OP) persona and entered information on my paternal grandfather and his parents rather than myself. I did this for two reasons: 1) I didn’t want to put information about me on the site 2) I suspected the system would have a much easier time finding information about my grandpa and his parents (all deceased) than about me and my parents (all living).
The wizard captured information about my grandpa and his parents and then took me to a pedigree view of the family (nowhere near as cool as the Super Duper Zim Zam Zoom Pedigree Viewer). When I got to the pedigree a pop-up instructed me that the twitching green leaf was an indicator that the system had found records of trees that might be about my family. I was excited to see that I had leaves in my pedigree.
I clicked on the leaf and saw that the system had found both trees and records. I chose to look at the records. I was pleased to find several records in a list of about 8 that were about my grandpa. I thought the flow of viewing records and then choosing to add them to my tree was pretty good. I did notice a few black holes in the flow that would have frustrated OPs. I loved that once I accepted a matching record I could choose how I wanted the transcribed data from the record to be reflected in my tree, the record cited itself (hooray!!) , and kept a link so that I can easily get to it from my tree.
I also took a look at some matching trees and grafted one into the line. The process was straightforward and the ability to choose how many generations to graft was a good compromise between being too granular to be functional and just stuffing the whole tree in.
I added a picture of grandpa's dad and even wrote a quick story about him. I found myself wishing that I could write a story about the picture or just include pictures in the story. The similarity between the flows for adding pictures and stories to a person and the prototypes that we've worked on over the past 18 months was uncanny. The flows were nearly identical and at times word usage and icons were also identical. That's not to say that either group was peaking at each others stuff, rather that we've both been studying the same problems and working toward very similar solutions.
Overall I found that the experience was conceptually on target and quite good for a first release. The timeline on the person page is somewhat lackluster and the overall feature set while not quite ready for OPs is a huge step in the right direction. The biggest weaknesses:
I put on my ordinary person hat and went to the site. I knew that there was some new tree building tool that would let me attach family artifacts to my tree, I just couldn’t find it. I had to take off my ordinary person hat to find the feature set which is located under the MyAncestry tab. The first thing I tried to do (which is probably not an ordinary person thing) was upload one of my GEDCOM files. For the life of me I couldn’t get the system to accept the file. I kept getting an error saying that it was an invalid GEDCOM file. The ordinary person in me was confused because I didn’t know what the error meant. The non-ordinary person in me was frustrated because I was feeding it the most plain GEDCOM file known to man which I’ve tested on nearly every system known to man and it was failing. This ended up being a good thing as it forced me to put my ordinary person hat back on and go down a different path.
The path I chose (which is more likely to be an ordinary person path) was to create a family tree. I found the wizard-style flow of the creation process to be straightforward and on target with the ordinary person side of me. I did step slightly out of the ordinary person (OP) persona and entered information on my paternal grandfather and his parents rather than myself. I did this for two reasons: 1) I didn’t want to put information about me on the site 2) I suspected the system would have a much easier time finding information about my grandpa and his parents (all deceased) than about me and my parents (all living).
The wizard captured information about my grandpa and his parents and then took me to a pedigree view of the family (nowhere near as cool as the Super Duper Zim Zam Zoom Pedigree Viewer). When I got to the pedigree a pop-up instructed me that the twitching green leaf was an indicator that the system had found records of trees that might be about my family. I was excited to see that I had leaves in my pedigree.
I clicked on the leaf and saw that the system had found both trees and records. I chose to look at the records. I was pleased to find several records in a list of about 8 that were about my grandpa. I thought the flow of viewing records and then choosing to add them to my tree was pretty good. I did notice a few black holes in the flow that would have frustrated OPs. I loved that once I accepted a matching record I could choose how I wanted the transcribed data from the record to be reflected in my tree, the record cited itself (hooray!!) , and kept a link so that I can easily get to it from my tree.
I also took a look at some matching trees and grafted one into the line. The process was straightforward and the ability to choose how many generations to graft was a good compromise between being too granular to be functional and just stuffing the whole tree in.
I added a picture of grandpa's dad and even wrote a quick story about him. I found myself wishing that I could write a story about the picture or just include pictures in the story. The similarity between the flows for adding pictures and stories to a person and the prototypes that we've worked on over the past 18 months was uncanny. The flows were nearly identical and at times word usage and icons were also identical. That's not to say that either group was peaking at each others stuff, rather that we've both been studying the same problems and working toward very similar solutions.
Overall I found that the experience was conceptually on target and quite good for a first release. The timeline on the person page is somewhat lackluster and the overall feature set while not quite ready for OPs is a huge step in the right direction. The biggest weaknesses:
- No help from the system in determining whether a matching tree or record is actually the right one. This is a huge issue. OPs need substantial help in making this determination. A set of visualization tools needs to be offered which allows the user to accurately make the decision without having to become a researcher.
- Access to the functionality is through the wrong door. Ancestry.com has done a great job at catering to the crowd from hobbyists to professional genealogists. Coming to Ancestry.com is a banquet for this group but a yawn or a nightmare for OPs. I would think that once the feature set is refined to where it really meets the needs of OPs the right door in is probably through a refreshed MyFamily.com.
- More could be done to increase the social networking opportunities within the tools. For example, as soon as I finish writing a story ask me if I want to share it with someone or if there is someone that can add more to the story.
Friday, October 27, 2006
Deodat's Descendants
One of my ongoing efforts in my own genealogical research has been a descendancy project. I've been trying to find all of the descendants of Deodat Brewster and Lois Drury (my GGGGGGGParents). Yesterday we added a descendancy view capability to the FamilySearch Labs site and used a portion of Deodat's descendancy as a sample file to look at. Take a look and let us know what you think.
I was thrilled the first time I pulled up Deodat's descendancy in the viewer and started looking around at (what seem like) familiar friends. I don't know why more people don't do descendancy research. Pursuing ancestors is a very 'western' approach to genealogy. There are many cultures around the world that have a hard time thinking of genealogy outside of the descendancy of an honored ancestor. After all, it doesn't start from me and go back, it starts from them and comes down.
I was thrilled the first time I pulled up Deodat's descendancy in the viewer and started looking around at (what seem like) familiar friends. I don't know why more people don't do descendancy research. Pursuing ancestors is a very 'western' approach to genealogy. There are many cultures around the world that have a hard time thinking of genealogy outside of the descendancy of an honored ancestor. After all, it doesn't start from me and go back, it starts from them and comes down.
Friday, October 20, 2006
Nothing Like Real Users
Wow, I love the 'labs' concept! 13 days ago we made the FamilySearch Labs site available. Since then the tool has processed about 3,000 pedigrees. We've received lots of feedback from real users on what they love and hate about the experience. Because of the volume and quality of the feedback we were able to quickly isolate and resolve usability issues.
We borrowed the idea from Google Labs to see if we could create an environment where we get user interaction with software substantially earlier in the development process. In the past we've often done paper prototyping to show concepts and task flows to users and get their feedback. Paper prototypes are good at helping you understand if you have the right elements on a page but don't do much to tell you if what your application will be useable. The labs approach has given us a whole new capability in useability testing.
While the labs experience has been a great success, it still doesn't remove the need for first hand observation of users. Here's an example. After we had resolved most of the major issues with the Smart Pedigree Viewer (thanks to Ben Crowther for the name) we decided to go and do some live observation. I spent some time at my favorite family history center watching people use the viewer. In twenty minutes I picked up a handful of usability issues that we never could have discovered without first hand observation. On the other hand, the amount of time we had to spend doing live observation to attain our currently level of useability was substantially reduced.
So what do I like about the labs site:
I could go on, but the point I'm making is that there is substantial value in the 'labs' concept. I HIGHLY recommend this approach to anyone developing consumer software. I know that some organizations will feel they can't be this open because their competitor will come look at the site too. My response: I believe speed, agility, openness, and community will beat fixed-length secrecy any day. They're going to see your product sooner or later.
We borrowed the idea from Google Labs to see if we could create an environment where we get user interaction with software substantially earlier in the development process. In the past we've often done paper prototyping to show concepts and task flows to users and get their feedback. Paper prototypes are good at helping you understand if you have the right elements on a page but don't do much to tell you if what your application will be useable. The labs approach has given us a whole new capability in useability testing.
While the labs experience has been a great success, it still doesn't remove the need for first hand observation of users. Here's an example. After we had resolved most of the major issues with the Smart Pedigree Viewer (thanks to Ben Crowther for the name) we decided to go and do some live observation. I spent some time at my favorite family history center watching people use the viewer. In twenty minutes I picked up a handful of usability issues that we never could have discovered without first hand observation. On the other hand, the amount of time we had to spend doing live observation to attain our currently level of useability was substantially reduced.
So what do I like about the labs site:
- Speed: We can change the application, put it on the site, and know if our new features sink or swim within a few hours.
- Audience: We've had users from all around the world looking at the application. This is critical for an application that will have an international reach.
- Cost: As you can imagine, gathering feedback on an application from several thousand users would be extremely expensive and virtually impossible. The cost to do this through the Labs site is trivial.
- Open: The labs culture of letting the users have a peak behind the curtain and sharing often imperfect software early and often creates an openness in communication between the developers and the users that I've never seen before.
- Motivation: Working in an environment that allows you to 'publish' your work every couple of days (or more often) is extremely motivating to the development team. It is exciting to get the newest thing into the hands of users.
- Community: Bringing the end user into the process helps us all feel like we're on the same team. It creates a sense of community. Everyone is invested in the outcome.
I could go on, but the point I'm making is that there is substantial value in the 'labs' concept. I HIGHLY recommend this approach to anyone developing consumer software. I know that some organizations will feel they can't be this open because their competitor will come look at the site too. My response: I believe speed, agility, openness, and community will beat fixed-length secrecy any day. They're going to see your product sooner or later.
Friday, October 06, 2006
FamilySearch (TM) Labs
A week or so ago I posted an image of my pedigree in a smart pedigree viewer we've been working on. Many people expressed an interest in playing with the viewer using their own data. We've just made a new website available (FamilySearch Labs) to showcase interesting new technology we're working on. The first project on the site is our smart pedigree viewer. It allows you to upload your own GEDCOM and view it or view one of our sample files. Go check it out at www.familysearchlabs.org and be sure to use the feedback link on the site to tell us what you think.
Monday, October 02, 2006
My Data or Our Data?
One of the ongoing debates in the genealogy industry is over who owns the data. This question has been analyzed in a number of ways including the legal/copyright angle. What's more interesting to me is how average people feel about the data they come across and piece together about their ancestors.
In some ways this debate reminds me of a favorite game my two oldest kids used to play whenever riding in the car. One would start the volley by saying: "He's my Dad!" The other would retort, "No, he's my Dad!" They would continue until the object of their debate became so enraged he ended the game for them (much to their dismay). After this they usually started another game: "I'm a boy!" "I'm a girl!" "Well, I'm a boy!" Those were the days.
At times I feel the same frustration over the debate on ownership of genealogical information. Here's a different way to look at the problem. Let's not talk about dead people, let's consider living people. Imagine that you have grandchildren (may be a stretch for some of you). Suppose that one of your grandchildren was digging through your filing cabinet and found your birth certificate. For some reason they didn't want to share it with the other grandchildren. Imagine another of your grandchildren really wanted a copy of the birth certificate so after some bargaining paid grandchild number 1 for a copy of the birth certificate with an agreement that he wouldn't show it to anybody else.
I know there are some gaping holes in the analogy but I do wonder how our ancestors feel about some of our strange attitudes toward the facts of their lives. The biggest hole in the analogy is that I do believe there can be a reasonable value exchange when one party has gone to some effort and expense to make information about our ancestors more easily available. The fee however should be for the service of making it accessible, not for the information. The information (in my opinion) is community property.
I've just put my kevlar vest on, I'm ready to post this, let the debate begin.
In some ways this debate reminds me of a favorite game my two oldest kids used to play whenever riding in the car. One would start the volley by saying: "He's my Dad!" The other would retort, "No, he's my Dad!" They would continue until the object of their debate became so enraged he ended the game for them (much to their dismay). After this they usually started another game: "I'm a boy!" "I'm a girl!" "Well, I'm a boy!" Those were the days.
At times I feel the same frustration over the debate on ownership of genealogical information. Here's a different way to look at the problem. Let's not talk about dead people, let's consider living people. Imagine that you have grandchildren (may be a stretch for some of you). Suppose that one of your grandchildren was digging through your filing cabinet and found your birth certificate. For some reason they didn't want to share it with the other grandchildren. Imagine another of your grandchildren really wanted a copy of the birth certificate so after some bargaining paid grandchild number 1 for a copy of the birth certificate with an agreement that he wouldn't show it to anybody else.
I know there are some gaping holes in the analogy but I do wonder how our ancestors feel about some of our strange attitudes toward the facts of their lives. The biggest hole in the analogy is that I do believe there can be a reasonable value exchange when one party has gone to some effort and expense to make information about our ancestors more easily available. The fee however should be for the service of making it accessible, not for the information. The information (in my opinion) is community property.
I've just put my kevlar vest on, I'm ready to post this, let the debate begin.
Wednesday, September 27, 2006
Scratch Pads
In the past I've blogged about the need for a scratch pad to assist in genealogical research. It is near impossible to do family history without some type of scratch pad to write down clues, organize your thoughts, do date math, build a timeline, draw a hypothetical pedigree, some potential sources I've found, etc. It would be great if these scratch pads could be persisted in the context of my current research.
Recently a colleague pointed me to an implementation of a scratch pad that is a good example of what could be implemented in a family history application. The scratch pad is implemented off to the right side of the search interface for MSN's Live Search. You can hide or show the scratch pad, drag search results onto the scratch pad and create groups of search results on a scratch pad. The next time you come back you can easily see the items you put on the scratch pad. Clicking on one of the items loads it in the main frame of the window.
There are many features you would want to add to make this useable for genealogy. For starters, the ability to add notes to the items on the scratch pad and to associate scratch pad items with people in your pedigree.
Take a look for yourself: http://search.msn.com/images/results.aspx#imagesize=all&q=pac-man
Recently a colleague pointed me to an implementation of a scratch pad that is a good example of what could be implemented in a family history application. The scratch pad is implemented off to the right side of the search interface for MSN's Live Search. You can hide or show the scratch pad, drag search results onto the scratch pad and create groups of search results on a scratch pad. The next time you come back you can easily see the items you put on the scratch pad. Clicking on one of the items loads it in the main frame of the window.
There are many features you would want to add to make this useable for genealogy. For starters, the ability to add notes to the items on the scratch pad and to associate scratch pad items with people in your pedigree.
Take a look for yourself: http://search.msn.com/images/results.aspx#imagesize=all&q=pac-man
Thursday, September 21, 2006
Not Just a Spot on a Pedigree
I believe when ordinary people think of genealogy a mental image of a pedigree chart with some names, dates, and places comes to mind. Average people aren't heavily engaged by this. If they don't know who the people are, they aren't likely to care. What is the magic blend of genealogical data and other artifacts from a person's life that changes them from a spot on a pedigree to a real person in the mind of their descendants?
I tried an experiment recently. I wanted to tell the story of an ancestor of mine with enough fidelity that a group of people, with no relationship to her, would come away realizing that she was not just a spot on a pedigree, she was a real person. I had 5 minutes to do it. That's not a lot of time to help them care about my ancestor. At the same time, it is an eternity to try and keep a group of people focused on a 'spot in a pedigree'. I decided to create a video that would highlight a few quick artifacts of her life. My objective was to have the group make the jump from 'spot on a pedigree' to 'real person' without saying a word. I've included the video below. Those of you that are not members of the LDS Church will notice that the video has strong LDS overtones.
I tried an experiment recently. I wanted to tell the story of an ancestor of mine with enough fidelity that a group of people, with no relationship to her, would come away realizing that she was not just a spot on a pedigree, she was a real person. I had 5 minutes to do it. That's not a lot of time to help them care about my ancestor. At the same time, it is an eternity to try and keep a group of people focused on a 'spot in a pedigree'. I decided to create a video that would highlight a few quick artifacts of her life. My objective was to have the group make the jump from 'spot on a pedigree' to 'real person' without saying a word. I've included the video below. Those of you that are not members of the LDS Church will notice that the video has strong LDS overtones.
Tuesday, September 19, 2006
A Better Pedigree
As I think about pedigrees, there is a short list of things I wish I could do. Many of them are influenced by applications like Google maps. For example, I wish that I could easily zoom in and out of my pedigree. All the way out would show my whole tree, all the way in would show a person or two. Then I wish I could just drag the pedigree to where I want to be rather than clicking and jumping a generation at a time.
Well, recently for a prototype we've been working on, we had to create a flash-based pedigree. We thought that rather than just do a knock-off of every pedigree out there, we'd try to implement some of these features. We determined it would take about the same time either way so we went for it. We learned some really interesting things.
1) There is a cool factor about being able to navigate a pedigree like this.
2) It is meaningful on multiple levels to be able to see your whole pedigree.
3) This pedigree seems to provide better context.
4) Interesting information can be communicated at a glance. For example, when my pedigree is all of the way zoomed out it is easy to see that I have a couple of holes in my 6th generation. This may be a logical starting point for some research.
Here is a screenshot of my pedigree all of the way zoomed out.
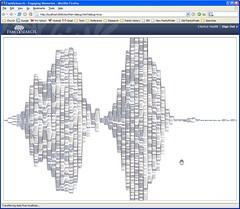
(Click for a larger view)
If you count you can see 54 generations (a cousin of mine hooked up to a royalty line that I left in for testing purposes...). You can't really see in the screenshot but as you mouse over people their ancestors all light up in one color and their descendants all line up in another color. If you click on a person their details pop up. We're considering putting this up on a server where people can play with it. Anyone interested?
Well, recently for a prototype we've been working on, we had to create a flash-based pedigree. We thought that rather than just do a knock-off of every pedigree out there, we'd try to implement some of these features. We determined it would take about the same time either way so we went for it. We learned some really interesting things.
1) There is a cool factor about being able to navigate a pedigree like this.
2) It is meaningful on multiple levels to be able to see your whole pedigree.
3) This pedigree seems to provide better context.
4) Interesting information can be communicated at a glance. For example, when my pedigree is all of the way zoomed out it is easy to see that I have a couple of holes in my 6th generation. This may be a logical starting point for some research.
Here is a screenshot of my pedigree all of the way zoomed out.
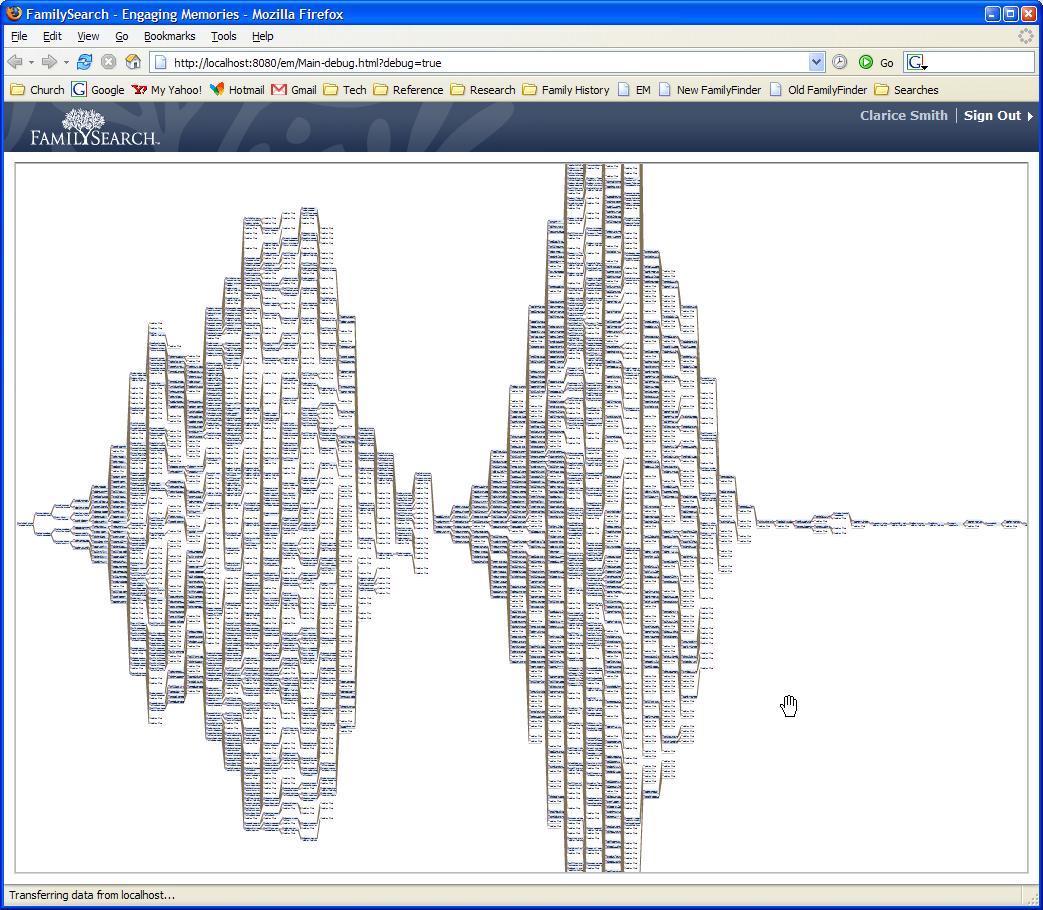
(Click for a larger view)
If you count you can see 54 generations (a cousin of mine hooked up to a royalty line that I left in for testing purposes...). You can't really see in the screenshot but as you mouse over people their ancestors all light up in one color and their descendants all line up in another color. If you click on a person their details pop up. We're considering putting this up on a server where people can play with it. Anyone interested?
Friday, September 01, 2006
Survey Results
Thanks to everyone that participated in the survey. There were a total of 64 responses. I've included the results below. I'd be curious about your interpretation of the results.
Here are the questions and their responses. Click on the thumbnails to see detailed responses.
1. What country and state do you live in?
Just less than half of the respondents live in Utah.
2. Do you know your grandparents' siblings?
We tend to know some of our grandparents' siblings.

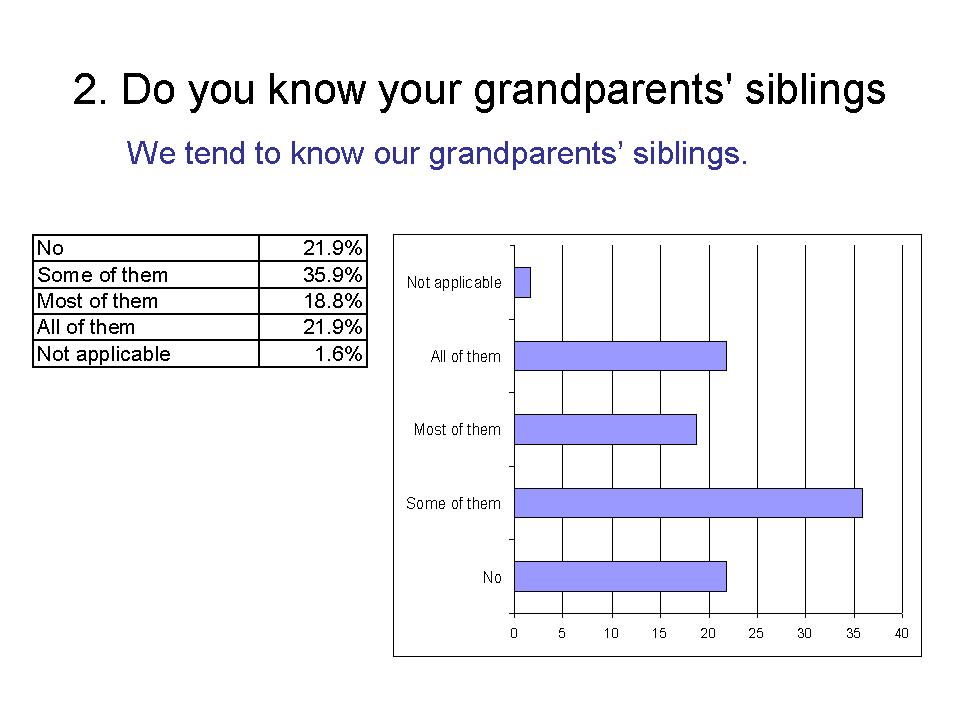
3. Do you know your grandparents' cousins?
We tend not to know our grandparents' cousins.

4. Do you know your parents' cousins?
We tend to know some of our parents' cousins.

5. Do you know your cousins?
We tend to know our cousins.

6. Do you know your nieces and nephews?
We tend to know all of our nieces and nephews.

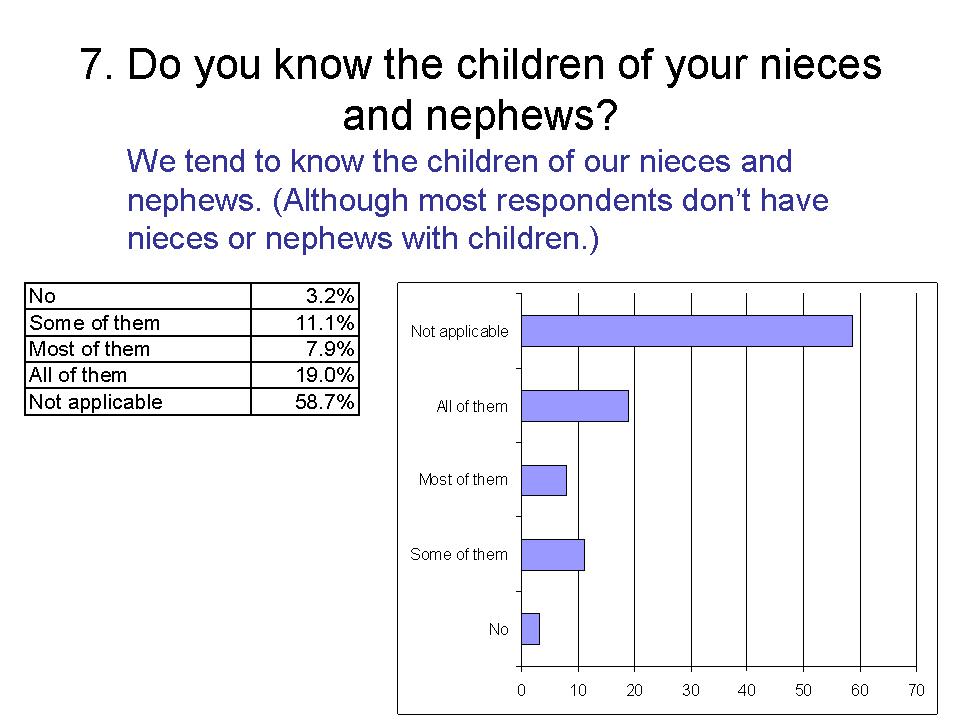
7. Do you know the children of your nieces and nephews?
We tend to know the children of our nieces and nephews. (Although most respondents don't have nieces or nephews with children)

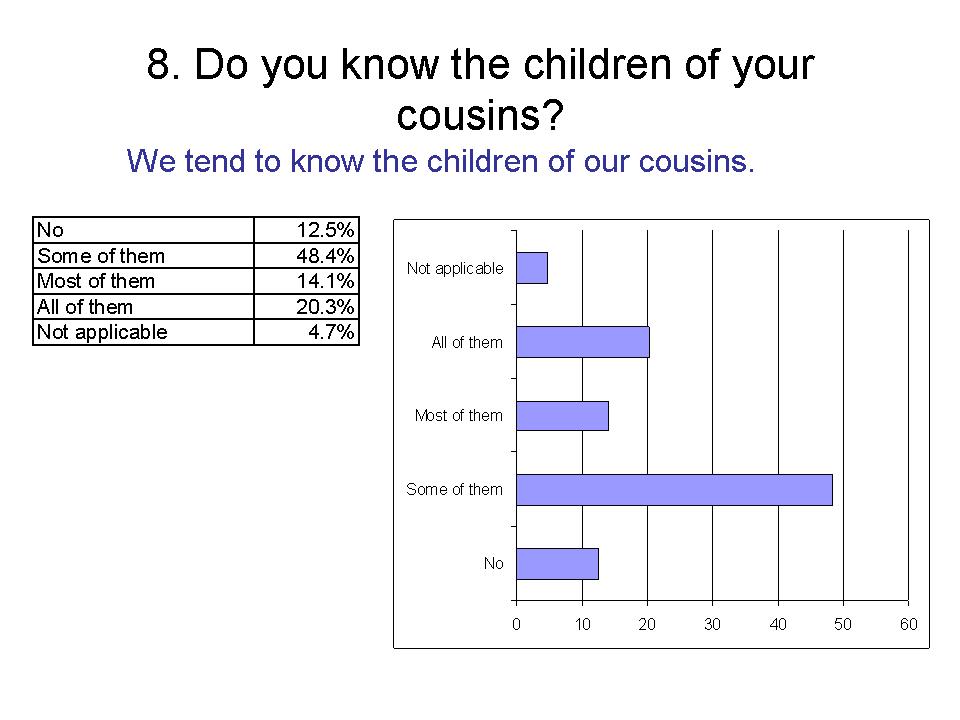
8. Do you know the children of your cousins?
We tend to know the children of our cousins.

9. Which of the following items have been obstacles in forming relationships with your relatives?
Almost 86% of respondents indicate that geographic distance has been an obstacle in forming relationships with relatives.

Here are the questions and their responses. Click on the thumbnails to see detailed responses.
1. What country and state do you live in?
Just less than half of the respondents live in Utah.

2. Do you know your grandparents' siblings?
We tend to know some of our grandparents' siblings.
3. Do you know your grandparents' cousins?
We tend not to know our grandparents' cousins.
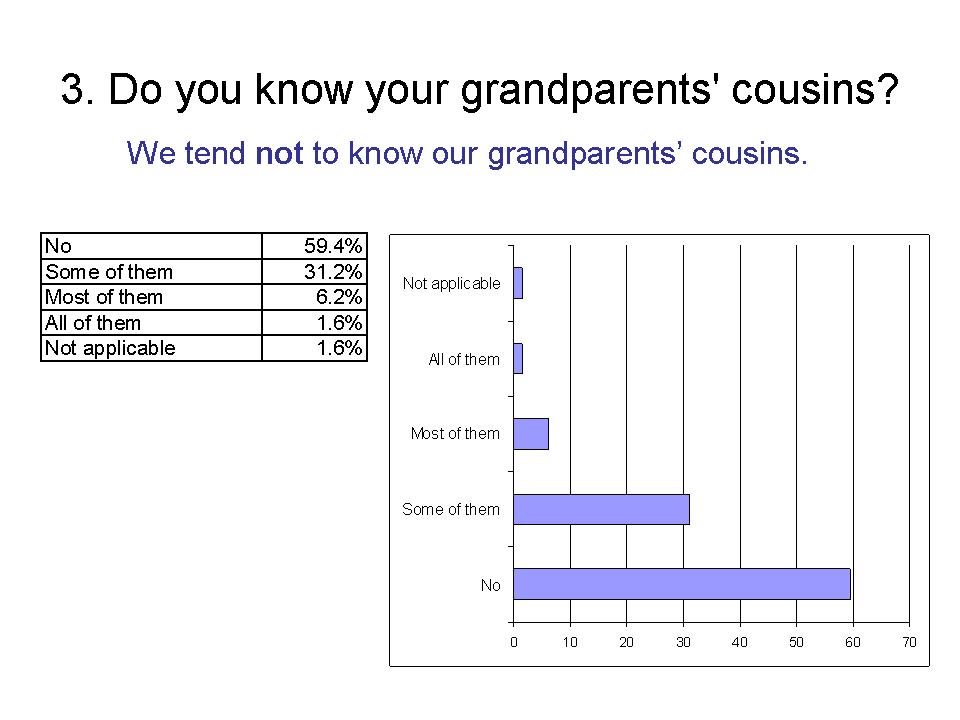
4. Do you know your parents' cousins?
We tend to know some of our parents' cousins.
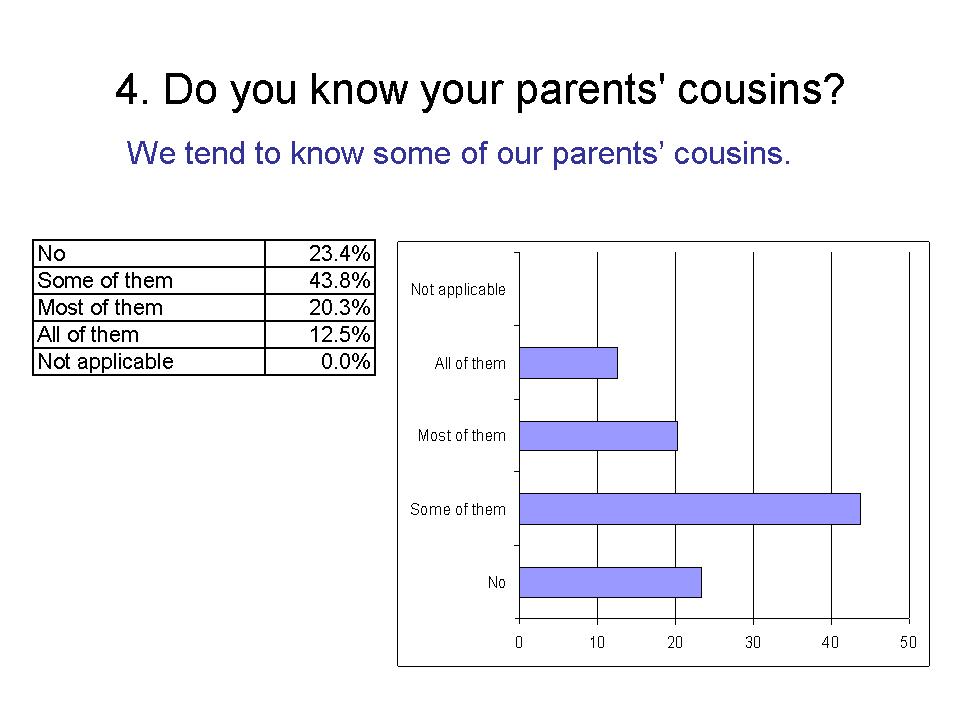
5. Do you know your cousins?
We tend to know our cousins.
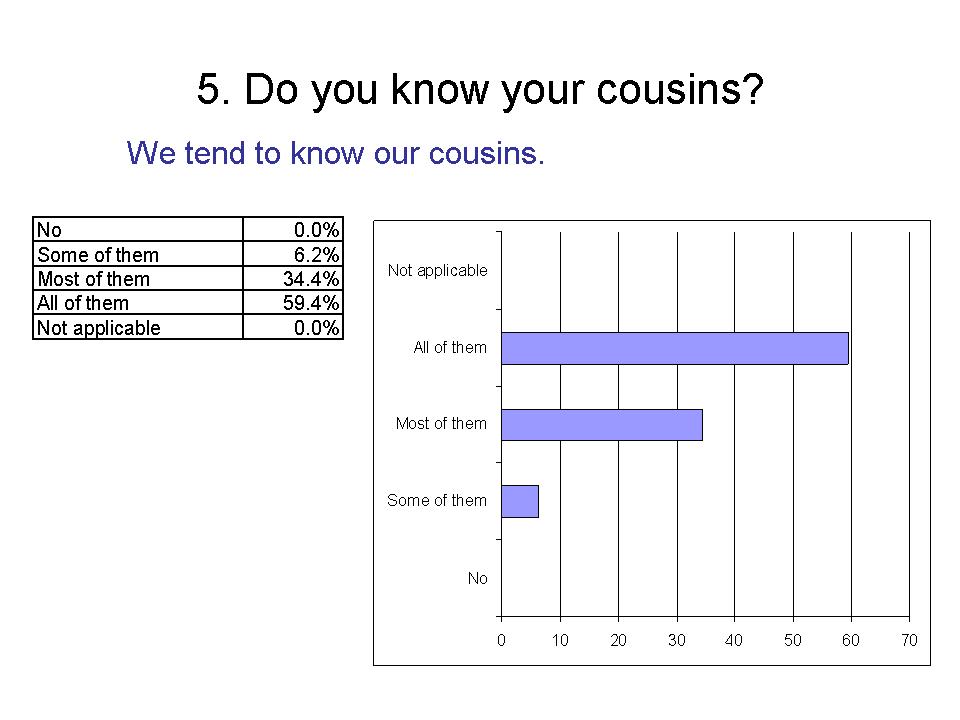
6. Do you know your nieces and nephews?
We tend to know all of our nieces and nephews.
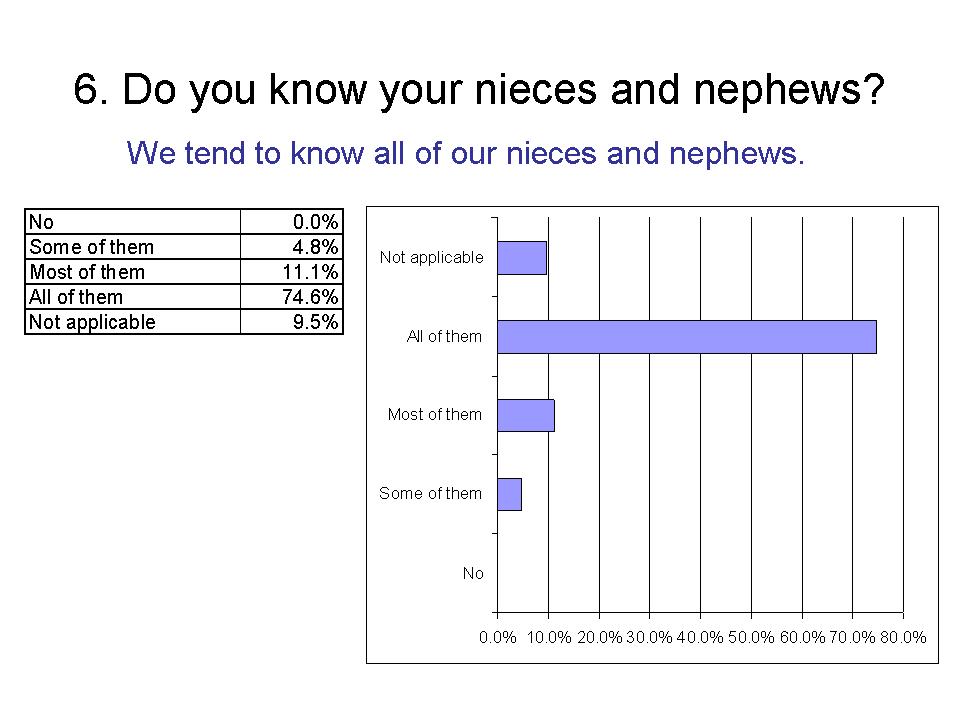
7. Do you know the children of your nieces and nephews?
We tend to know the children of our nieces and nephews. (Although most respondents don't have nieces or nephews with children)
8. Do you know the children of your cousins?
We tend to know the children of our cousins.
9. Which of the following items have been obstacles in forming relationships with your relatives?
Almost 86% of respondents indicate that geographic distance has been an obstacle in forming relationships with relatives.

Friday, August 11, 2006
How Well do You Know Your Relatives?
Over the last week we've been discussing what I call the 'family reunion effect'. If you've ever been to a family reunion which included people beyond your parents posterity, you've probably experienced it. You meet someone you don't know. You suspect they are related to you - after all, you're at the same family reunion. You quickly figure out how you are related.
There is something about being together with people that you think you're related to that makes you want to know who your common ancestors are. Interacting with your living relatives creates a natural draw toward your common ancestors. It is often a natural entry point to doing (or atleast discussing) family history. This 'family reunion effect' has made us want to know more about how people interact with their relatives and if there are natural ways in which this interaction can be used to introduce family history activities. As a starting point I put together a quick survey trying to see if there are common boundaries to which relatives we know. Please take a moment and fill out the survey. I'll share the results on the blog.
Click here to take survey
Feel free to invite others to participate in the survey.
There is something about being together with people that you think you're related to that makes you want to know who your common ancestors are. Interacting with your living relatives creates a natural draw toward your common ancestors. It is often a natural entry point to doing (or atleast discussing) family history. This 'family reunion effect' has made us want to know more about how people interact with their relatives and if there are natural ways in which this interaction can be used to introduce family history activities. As a starting point I put together a quick survey trying to see if there are common boundaries to which relatives we know. Please take a moment and fill out the survey. I'll share the results on the blog.
Click here to take survey
Feel free to invite others to participate in the survey.
Wednesday, August 02, 2006
More on the Problem
Well I’ve been silent for a while. Not that I’ve stopped thinking about the problem of making genealogy accessible to ordinary people. Rather, I’ve been up to my eyeballs in it.
In an effort to describe the problem more fully, here is some information from a test we did last year.
We did some user testing in August of 2005. I won’t disclose the whole scenario but we basically provided a deep set of records for a contiguous set of counties in one state in the US. The records were all digitized and indexed. We took extreme care to find a broad range of users to test making sure that none of them had previously done genealogical research. Then we gave users a shallow pedigree of a family that lived in those counties for several generations and access to the records. The users were extremely successful at deepening the pedigree. One possible interpretation of the test results is that if regular people have easy access to digitized, indexed records, they can succeed. That’s not to say there weren’t some problems along the way.
One of the activities we did to try to understand the results of the test was to build an affinity diagram of all the important things we observed during the test. Here are some of the key learnings from the affinity diagram.
In an effort to describe the problem more fully, here is some information from a test we did last year.
We did some user testing in August of 2005. I won’t disclose the whole scenario but we basically provided a deep set of records for a contiguous set of counties in one state in the US. The records were all digitized and indexed. We took extreme care to find a broad range of users to test making sure that none of them had previously done genealogical research. Then we gave users a shallow pedigree of a family that lived in those counties for several generations and access to the records. The users were extremely successful at deepening the pedigree. One possible interpretation of the test results is that if regular people have easy access to digitized, indexed records, they can succeed. That’s not to say there weren’t some problems along the way.
One of the activities we did to try to understand the results of the test was to build an affinity diagram of all the important things we observed during the test. Here are some of the key learnings from the affinity diagram.
- People aren’t used to thinking backward through time (death to birth) they are much better at thinking about a person’s life moving forward (birth to death).
- People start with false assumptions that blind their ability to see the truth. For example, one user assumed that husbands were always older than wives and incorrectly determined that the wife’s age must be wrong because she was older than her husband.
- Searching on the Internet is not intuitive. Too many or too few search results confuse the user. If there really are no search results, the user should be offered an alternate strategy. For example, if the user searches a census for Bob Johnson in Geneva twp, Walworth Co, Wisconsin and their aren’t any why can’t the system come back with results that say there are no Bob Johnsons in Geneva twp but there are three in Walworth County, would you like to see those?
- Two strikes and you’re out. Users give search features about two chances before they determine if it is worthwhile or not.
- Ordinary people seem unwilling to pursue offline sources. They greatly prefer the immediacy of the Internet. Perhaps one of the key measures of the state of the industry should be the mean time for an ordinary person to access a record. Right now I’d guess it is 3 weeks.
- Users want to save the sources that they find but it is hard. Take a look at clipmarks.com for an interesting way to capture online content.
- Users have a hard time harvesting appropriate information from a record. One user looking at a census record and talking out loud said, “Years married. Hmm… I don’t need to know that.” The problem of knowing what was meaningful in a record seemed particularly acute when the information was indirect evidence. Forms seemed to help the user get more out of the records.
- Unfamiliar names and variance in names and dates confused the users.
- Users need tools to add context and compensate for their inexperience. Things like maps, history, and date calculators would be a great help.
- Users need to be able to capture clues and get back to them easily in their original context.
- Users need a place for temporary conclusions – a working draft of their pedigree.
- Users need help knowing when to draw a conclusion. They struggle with match analysis.
- Users need substantial help keeping everything they are seeing and doing in context. Experienced genealogists are able to keep it all in their head, novices aren’t.
Thursday, May 25, 2006
Trust Model
Have you ever used an application that violated your trust? Maybe it didn’t save something when you thought it should have or maybe you unexpectedly came across you and all of your living relatives in some online pedigree. One of the subtleties to successful applications is not breaking the user’s trust model. There are numerous ways in which the current array of family history tools violates people’s trust.
As family history applications become increasingly more collaborative in nature one of the primary issues to be considered has to do with sharing data. Using large brush strokes I can describe the trust model that users expect with regard to collaborating on their family history. Users tend to break their data down into three large chunks: my stuff, my shared stuff, and my published/public stuff. Notice that in all three cases they view it as my stuff. The difference is in who they are allowing to see their stuff. If the user were to encounter an application that doesn’t support this model they are likely to either abandon the tool or augment it. For example, if they used a tool that immediately published all of their work to the world, they would likely not use the tool. Instead, they would keep all of their stuff and their shared stuff someplace else until they were ready to publish. If they didn’t realize the tool was going to immediately publish and they used it, they would likely feel so burned by the experience that they would never come back.
The challenge to this is that fundamentally if people will share sooner they will make faster progress on their family history. They will more quickly find others working on the same problems that may already have the answer or can at least offer help. So how do we build a new generation of family history tools that support the user’s trust model but also encourage the user to share and publish sooner? Here are four ideas.
In summary…
As family history applications become increasingly more collaborative in nature one of the primary issues to be considered has to do with sharing data. Using large brush strokes I can describe the trust model that users expect with regard to collaborating on their family history. Users tend to break their data down into three large chunks: my stuff, my shared stuff, and my published/public stuff. Notice that in all three cases they view it as my stuff. The difference is in who they are allowing to see their stuff. If the user were to encounter an application that doesn’t support this model they are likely to either abandon the tool or augment it. For example, if they used a tool that immediately published all of their work to the world, they would likely not use the tool. Instead, they would keep all of their stuff and their shared stuff someplace else until they were ready to publish. If they didn’t realize the tool was going to immediately publish and they used it, they would likely feel so burned by the experience that they would never come back.
The challenge to this is that fundamentally if people will share sooner they will make faster progress on their family history. They will more quickly find others working on the same problems that may already have the answer or can at least offer help. So how do we build a new generation of family history tools that support the user’s trust model but also encourage the user to share and publish sooner? Here are four ideas.
- Help the user always feel like it is their stuff. They own it. If they share it with you always allow them to get it back.
- Provide at least the three mental buckets: my stuff, my shared stuff, and my published/public stuff. This does not imply complex access control systems. The simplest form can be stuff that only I can see, stuff that people on my shared list can see, and stuff everyone can see. More and more I find complex grouping concepts in sharing to be too much for ordinary people. I really like the way Flickr.com has implemented this. Here is a snapshot of their access control.
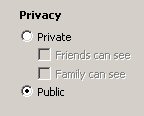
- Allow the flow of the program to encourage people to move their data from my stuff to my shared stuff to my published/public stuff as quickly as possible. Offer carrots to do it. For example, an application might look at my stuff and compare it to someone else’s stuff and then notify me that it looks like someone else is working on really similar stuff and ask if I’d like to contact that user and share some of my stuff.
- Allow the user to say “I think” or “Maybe” about their conclusions. This is an area of functionality that is tempting to make overly complex. You could build a whole feature set around analyzing the quality of evidence, a surety schema, etc., etc. Ordinary people are likely to be driven off by this. One simple way to implement this might be to have a flag or button associated with fields that indicate that the conclusion is really a hypothesis of sorts. This would allow the user to share their work in progress with others without losing that important piece of metadata “I think”. Systems could also be more cautious about how they propagate things marked with an “I think” flag.
In summary…
- If an application doesn’t support the user’s trust model they won’t use it.
- The user definitely has a trust model around collaboration.
- We need to support the user’s trust model while facilitating faster, more frequent collaboration.
Wednesday, April 26, 2006
Family History Technology Workshop
This past March the 6th annual Family History Technology Workshop was held at Brigham Young University. I've been waiting for the presentations to be posted online so that I could offer some commentary about some of the topics discussed at the conference and reference the presentations. The slides for each of the presentations referenced below can found here.
Peter Norvig, Director of Research at Google
There was a lot of great content in Peter’s Key Note address Thursday morning. The thing that stuck out the most in my mind was the philosophy of recall versus precision when searching a data set. The basic philosophy Peter presented seemed to be that when you are dealing with sufficiently large quantities of data your recall (as a percentage of the total data set) can be low and precision extremely high.
Matthew Smith and Christophe Giraud-Carrier – Genealogical Implicit Affinity Network
Matthew presented their work on a Genealogical Implicit Affinity Network. This was totally cool. They took GEDCOM files and mined them for affinities between interesting data points, some examples offered were relationships, naming patterns and occupations. The results were presented as hyperbolic tree-like affinity diagrams. I think there is something in this that with some refinement would help ordinary people to have a greater interest and appreciation for their ancestors, not to mention the practical value of the data in research. I was so fascinated that with their presentation that a few weeks ago we visited them in their lab to have a follow on conversation. I hope to do a separate blog posting specific to this. If you’d like to find out more about their work visit the data mining lab website.
Shane Hathaway and the Touchstone Team – The Bit Mountain Research Project
Shane gave a great presentation on what it takes to build an 18 petabyte system that can be preserved long-term.18 petabytes is the projected storage capacity that will be required overtime for the new family history system the Church is developing. This is an area where the Church’s needs appear to be ahead of the industry’s capability. The paper submitted for this session (as with the other sessions) contains much more information than what could be presented in the 20 minute time slot. It describes the use of forward error correction in a distributed file system to deliver a ‘self-healing’ data store for applications.
Dallan Quass – Identifying Genealogical Content on the Web
Dallan is heading up a non-profit organization called the Foundation for On-Line Genealogy. He presented some research about their efforts to determine the best way to search for genealogical information on the web. Finding a more effective way to search the web for genealogical data is key to making genealogy more palatable for ordinary people. I’m excited by the work Dallan’s organization is doing. You can learn more about this and other efforts at WeRelate.org.
Grant Skousen – Family Finder Prototype
Grant presented an overview of a software prototype designed to help ordinary people (read: have never done genealogy) find their ancestors. The results of the research were promising. This project is one that I became involved with near the end. It has been extremely valuable in helping to shape thoughts around what it takes to help ordinary people to family history. I hope to do a future posting offering more insight into the research. For now, be sure to review this presentation.
Randy Wilson – High-Level View of a Source-Centric Genealogical Model
Randy presented a conceptual framework for a system that would change genealogy from an unbounded task to a finite effort. I believe Randy’s proposal is on target and that such a system must be created as the foundation of an effort to make genealogy work for the ordinary person. One of the primary points of frustration to those that contemplate finding their ancestors is knowing what has already been done and knowing where to start. Randy’s paper and slides are definitely worth reviewing.
Peter Norvig, Director of Research at Google
There was a lot of great content in Peter’s Key Note address Thursday morning. The thing that stuck out the most in my mind was the philosophy of recall versus precision when searching a data set. The basic philosophy Peter presented seemed to be that when you are dealing with sufficiently large quantities of data your recall (as a percentage of the total data set) can be low and precision extremely high.
Matthew Smith and Christophe Giraud-Carrier – Genealogical Implicit Affinity Network
Matthew presented their work on a Genealogical Implicit Affinity Network. This was totally cool. They took GEDCOM files and mined them for affinities between interesting data points, some examples offered were relationships, naming patterns and occupations. The results were presented as hyperbolic tree-like affinity diagrams. I think there is something in this that with some refinement would help ordinary people to have a greater interest and appreciation for their ancestors, not to mention the practical value of the data in research. I was so fascinated that with their presentation that a few weeks ago we visited them in their lab to have a follow on conversation. I hope to do a separate blog posting specific to this. If you’d like to find out more about their work visit the data mining lab website.
Shane Hathaway and the Touchstone Team – The Bit Mountain Research Project
Shane gave a great presentation on what it takes to build an 18 petabyte system that can be preserved long-term.18 petabytes is the projected storage capacity that will be required overtime for the new family history system the Church is developing. This is an area where the Church’s needs appear to be ahead of the industry’s capability. The paper submitted for this session (as with the other sessions) contains much more information than what could be presented in the 20 minute time slot. It describes the use of forward error correction in a distributed file system to deliver a ‘self-healing’ data store for applications.
Dallan Quass – Identifying Genealogical Content on the Web
Dallan is heading up a non-profit organization called the Foundation for On-Line Genealogy. He presented some research about their efforts to determine the best way to search for genealogical information on the web. Finding a more effective way to search the web for genealogical data is key to making genealogy more palatable for ordinary people. I’m excited by the work Dallan’s organization is doing. You can learn more about this and other efforts at WeRelate.org.
Grant Skousen – Family Finder Prototype
Grant presented an overview of a software prototype designed to help ordinary people (read: have never done genealogy) find their ancestors. The results of the research were promising. This project is one that I became involved with near the end. It has been extremely valuable in helping to shape thoughts around what it takes to help ordinary people to family history. I hope to do a future posting offering more insight into the research. For now, be sure to review this presentation.
Randy Wilson – High-Level View of a Source-Centric Genealogical Model
Randy presented a conceptual framework for a system that would change genealogy from an unbounded task to a finite effort. I believe Randy’s proposal is on target and that such a system must be created as the foundation of an effort to make genealogy work for the ordinary person. One of the primary points of frustration to those that contemplate finding their ancestors is knowing what has already been done and knowing where to start. Randy’s paper and slides are definitely worth reviewing.
Monday, April 17, 2006
What Do Ordinary People Want?
There have been some great discussions going on in the comments of this blog and through other forums. John Vilburn recently expressed well the fundamental purpose of this blog. John said:
That really is the core of the problem my team is dealing with every day. It sounds simple but it is a monumental challenge. It is hard for people who think that the status quo experience with genealogy is interesting to understand what it would take for the rest of the world to share our sentiment. So what is it that will capture the interest of ordinary people? How do you take that interest and convert it into actions that will successfully find ancestors without the interest waning? Here are some interesting things we’ve learned about what gets and keeps the interest of ordinary people.
Please comment and add to the list of things that would interest ordinary people.
| Making genealogy engaging for the common person requires a broader vision. A big part of that is using technology to make genealogy easier. But the more important question is "What makes genealogy engaging to someone who has no experience?" |
That really is the core of the problem my team is dealing with every day. It sounds simple but it is a monumental challenge. It is hard for people who think that the status quo experience with genealogy is interesting to understand what it would take for the rest of the world to share our sentiment. So what is it that will capture the interest of ordinary people? How do you take that interest and convert it into actions that will successfully find ancestors without the interest waning? Here are some interesting things we’ve learned about what gets and keeps the interest of ordinary people.
- Sharing pictures, records, maps, audio clips and other artifacts of their family. Ordinary people love to see pictures of their ancestors, the records of their lives and any other artifact related to an ancestor. In some ways this is like scrapbooking. As they look at these items they are trying to get a sense of the ancestor’s life journey. They are trying to find the parallels between themselves and their roots. Even items which aren’t directly about their family but are from the same place or time can add meaningful texture.
- Stories. Ordinary people are interested in stories about their family. Again, they seem to be trying to appreciate the life of the ancestor. Learning about the ancestor somehow helps them understand themselves better. It boosts their self-worth to realize that their ancestor did something great, funny, unique or just survived. While stories that relate directly to an ancestor are most meaningful, some stories that are about others in similar places, times and events are also meaningful. Stories add texture.
- A sense of community. This is an area we are just starting to explore. There seems to be something appealing to ordinary people in just knowing that others are interested in the same people, stories, pictures, times and places and being able to communicate with them. The ability to see who else is interested is powerful.
- A sense of relation. Ordinary people seem to like knowing how they are related to others (both living and deceased). They aren’t very good at figuring this out themselves but are interested in the information when it is offered.
- Immediacy. Ordinary people (at least in 1st world countries) have an expectation of immediacy. They don’t want to search for a picture or record of an ancestor, find out where it is and then write a letter to request a copy or wait 3 weeks for a microfilm to come in. If they can’t see something immediately they aren’t likely to be interested.
- Short bursts of time. You have a matter of seconds to convince someone coming to a website that they’ve come to the right place. Once you’ve got them to stay on your home page you have a few more seconds for them to determine how to access what they’re looking for. If you’re lucky they’ll give you two tries to produce the desired result. Once they’re convinced that the desired results are available you may get them to give you 5 or 10 minutes of their time. I point this out not because I think all genealogy experiences are web-based but because it shows how sensitive ordinary people are to succeeding in short bursts of time. Ordinary people need to get something meaningful done in 10 minutes or less. When they come back to the activity later they need to be able to pick up where they left off without losing any time.
- Don’t want to be trained. Ordinary people (varies slightly by culture) don’t want to read the manual and don’t want to take a class. We cannot rely on manuals or training to get ordinary people involved.
- Don’t like to feel stupid. Ordinary people don’t like to feel stupid (as it turns out this isn’t limited to ordinary people). There are some classic examples of this but one that is fairly ubiquitous is search. There are lots of ways to stump people with search: complex search forms; pages and pages of ambiguous results; and my favorite, 0 results.
Please comment and add to the list of things that would interest ordinary people.
Wednesday, April 05, 2006
Making Genealogy Accessible
The predominant approach of those trying to help novices engage in genealogy is to attempt to train them to do research. There are some that are extremely skilled in this area and have made a substantial contribution to the ranks of genealogy hobbyists and credentialed genealogists. There will always be a need for those with the rare talent of helping someone along the path toward sound genealogical research.
Last summer Ancestry.com issued a press release indicating that according to a recent poll, 73% of Americans are interested in discovering their family history. Most of us have seen similar studies before. In the context of taking genealogy to common people, the question could be asked, “How do we get 73% of Americans to participate meaningfully in family history?” It is probably not feasible to get them all through a genealogy class or paired with a great mentor. It also seems that a relatively small percentage of those interested in their ancestors are able to do genealogical research. This is not a derogatory comment about average intellect but a recognition that there are many factors beyond cognitive skills which prevent people from doing genealogical research.
So if the intention is to take genealogy to common people, how can it be done? The philosophy behind this blog is not to attempt to turn 73% of Americans into researchers. Rather, it is to encourage innovation that makes the experience of genealogy substantially easier and more engaging than it is today. Make it so that individuals don’t have to become researchers in order to have success finding their family history. Simplify genealogy for researchers or those that want to become researchers as much as possible.
This will require technology to do much of the heavy lifting for the uninitiated. There are many examples that could be drawn upon to illustrate this type of shift. Some that we are all familiar with include:
One of the most interesting things about these shifts from a domain of experts toward pervasive use is the increasing rate at which they happen. Some recent shifts that are happening quickly but not yet complete:
We are not attempting to teach 73% of Americans to be genealogists. We are attempting to make genealogy accessible to 73% of Americans.
Last summer Ancestry.com issued a press release indicating that according to a recent poll, 73% of Americans are interested in discovering their family history. Most of us have seen similar studies before. In the context of taking genealogy to common people, the question could be asked, “How do we get 73% of Americans to participate meaningfully in family history?” It is probably not feasible to get them all through a genealogy class or paired with a great mentor. It also seems that a relatively small percentage of those interested in their ancestors are able to do genealogical research. This is not a derogatory comment about average intellect but a recognition that there are many factors beyond cognitive skills which prevent people from doing genealogical research.
So if the intention is to take genealogy to common people, how can it be done? The philosophy behind this blog is not to attempt to turn 73% of Americans into researchers. Rather, it is to encourage innovation that makes the experience of genealogy substantially easier and more engaging than it is today. Make it so that individuals don’t have to become researchers in order to have success finding their family history. Simplify genealogy for researchers or those that want to become researchers as much as possible.
This will require technology to do much of the heavy lifting for the uninitiated. There are many examples that could be drawn upon to illustrate this type of shift. Some that we are all familiar with include:
- the shift from paying a telegraph operator to send a message for you to picking up the phone and calling someone
- the shift from professional typists to ubiquitous e-mail
- the shift from professional photography to point and shoot to digital cameras
One of the most interesting things about these shifts from a domain of experts toward pervasive use is the increasing rate at which they happen. Some recent shifts that are happening quickly but not yet complete:
- blogging
- video editing
- podcasting
We are not attempting to teach 73% of Americans to be genealogists. We are attempting to make genealogy accessible to 73% of Americans.
Wednesday, March 29, 2006
Raising the Bar for Record Managers
Most people that get involved with genealogy today use a family history application called a record manager to store and navigate lineage-linked genealogical information. There are many to choose from. Some of the more common are Personal Ancestral File (PAF), Family Tree Maker, Legacy Family Tree, AncestralQuest, RootsMagic and the Master Genealogist. There are also a range of online record managers like phpGedView, The Next Generation and PedigreeSoft which in some respects are more cumbersome than the traditional desktop applications but offer the advantage of ease of sharing and collaboration.
While these applications are very effective at organizing lineage-linked data, the user experience and complexity is on par with filing your taxes (my apologies to the makers of these products, I know most of them and hope they don’t take offense at this observation).
There have been a couple of interesting advances in the space over the last few years. Notably, the move toward online record managers (phpGedView,) and research guidance (Legacy 6) definitely show promise. So in the spirit of taking genealogy to common people, here is my top ten list of what it would take to raise the bar for record managers.
Top 10 Innovations Needed in Record Managers
I'd be happy to engage in a deeper conversation of how to take record managers to the next level. Add your comments or e-mail me (lawyerdc@ldschurch.org).
While these applications are very effective at organizing lineage-linked data, the user experience and complexity is on par with filing your taxes (my apologies to the makers of these products, I know most of them and hope they don’t take offense at this observation).
There have been a couple of interesting advances in the space over the last few years. Notably, the move toward online record managers (phpGedView,) and research guidance (Legacy 6) definitely show promise. So in the spirit of taking genealogy to common people, here is my top ten list of what it would take to raise the bar for record managers.
Top 10 Innovations Needed in Record Managers
- Living memory interview – I have personally done usability testing and observed ordinary people taking 30 minutes to an hour to figure out how to enter themselves and their parents into a record manager. When someone starts fresh in a record manager why isn’t one of the options to start a new file from what I know? This option would lead the user through a nice wizard-like living memory interview.
- Path to me – Once you browse a few generations it is impossible to tell which path leads back to me. Isn’t there a simple way to add this bit of information to the UI?
- Maps, maps, maps – Google Maps, Google Earth, open APIs, need I say more? Maybe not but I will. Users need current and historical maps for research. Seeing a historical map helps me feel connected to my ancestors. Overlaying data on maps is interesting. For example, migration patterns on maps, plotting the events of an ancestors life on a map, showing the overland trail they used to come west, showing the plat map of the town they lived in. Showing everyone with the first name of Deodat living in the US in 1850 census.
- Context – Users need lots of context to hold their interest, keep oriented, and to aid in research. Maps (as mentioned above), history (as mentioned in a previous article - record managers really need to integrate with WeRelate.org), historical texture (music of the time, clothes of the time, the price of gas) and anything else you can think of.
- Clue Pad/Scratch Pad – This ties back to the need for context. Users need a scratch pad to keep their clues on. The scratch pad needs to let them get back to the clue in context of their pedigree and the source information they were evaluating. It also needs to let them model simple things like: “The wife of John Smith is either Mary Jones or Mary Johnson,” and still keep them in context of the clues that led them to this theory.
- Automatic source citations – There has been a lot of dialog on this blog about self-citing Internet sources. Record managers must support this functionality moving forward.
- Improved match analysis – I’m not talking about the underlying algorithms (although they are an area of constant improvement). I’m talking about the user interface. How can a novice reliably and consistently make decisions about possible matches in 30 seconds or less? Here are some rough concepts we’ve played with to try and figure this out. They still need lots of work but show how match analysis can be much more than the status quo screens in most record managers.



- Interesting Charts – Lines and boxes were cool when dot matrix printers were the rage. Rounded corners had their day as well. Give me a chart that I can put on my wall and my kids, relatives, friends, anyone who walks in the door will notice and want to look at and not mistake it for an electrical diagram. Add historical texture to the charts, themed backgrounds, etc.
- Source citation wizard – While I strongly advocate self-citing sources for online content, the reality is we will need to deal with manual source citations for a long time. Let’s build a simple wizard, similar to CitationMachine.net to make it drop-dead simple to cite a source.
- Personal Research Assistant/Research guidance – Legacy 6 is moving in the right direction but their feature set works better for advanced genealogists and not ordinary people. Take a look at Grant Skousen’s Family Finder presentation from the BYU Family History Technology Workshop (should be posted in a week or so) to get a feel for how to deliver this for the uninitiated.


I'd be happy to engage in a deeper conversation of how to take record managers to the next level. Add your comments or e-mail me (lawyerdc@ldschurch.org).
Friday, March 24, 2006
Give Me Context
Last summer I spent some time conducting user testing of a software prototype designed to help ordinary people find their ancestors. There was an overview of this prototype and the results of our testing presented at the recent Family History Technology Workshop held at BYU a couple of weeks ago. Definitely worth checking out the slides and abstract information when it comes online. One of the things that really stood out in the testing was the amount of context a user required to be able to do genealogical research. Here is a quote from one of the users while looking at a census record which exemplifies the problem, "I need a map, a calculator and a really smart person at my side [to understand this census record]."
Here are a few pieces of context that users seem to always need in view in order to understand family history:
I've seen some interesting mashups trying to put one or more of these pieces of context together. For example, the following two sites have interesting mashups with google maps: www.linkr.org, www.linkr.org/temples. Of these important elements of context, history and historical maps are particularly hard to deliver dynamically in the context of family history. I believe it is due to the lack of an easily searchable and addressable collection of content. Wouldn't it be great if there was a public domain data set with a rich API for searching and distributing this type of content in context? Perhaps this is something that the guys at WeRelate.org can take on. Simply link the history and historical maps to their location authority, make the data elements addressable with sufficient granularity and provide an API. Oh yeah, and get a bunch of people to help populate the content.
Here are a few pieces of context that users seem to always need in view in order to understand family history:
- Maps (current and historical)
- History (local, national, world)
- Timeline
- Pedigree
I've seen some interesting mashups trying to put one or more of these pieces of context together. For example, the following two sites have interesting mashups with google maps: www.linkr.org, www.linkr.org/temples. Of these important elements of context, history and historical maps are particularly hard to deliver dynamically in the context of family history. I believe it is due to the lack of an easily searchable and addressable collection of content. Wouldn't it be great if there was a public domain data set with a rich API for searching and distributing this type of content in context? Perhaps this is something that the guys at WeRelate.org can take on. Simply link the history and historical maps to their location authority, make the data elements addressable with sufficient granularity and provide an API. Oh yeah, and get a bunch of people to help populate the content.
Tuesday, March 21, 2006
Embedded Citation Examples
I have seen a few examples of embedded citations in the past few weeks. I would love to get a more complete list of good examples of sites that already have embedded citations. If you are aware of them please leave a comment with some links to exampls sites or send me an e-mail, lawyerdc@ldschurch.org.
One site that comes to mind is fact monster. They have a simple implementation with a link at the bottom of each page that opens a pop-up with the citation detail. Follow this link and look at the bottom of the page for the button.
button.
A co-worker (thanks Steve) also sent me information about a NISO standard called OpenURL 1.0 (Z39.88-2004) which has come out of the library information community as a means to embed citation metadata in webpages. More detail can be found at the OpenURL COinS website.
One site that comes to mind is fact monster. They have a simple implementation with a link at the bottom of each page that opens a pop-up with the citation detail. Follow this link and look at the bottom of the page for the
button.A co-worker (thanks Steve) also sent me information about a NISO standard called OpenURL 1.0 (Z39.88-2004) which has come out of the library information community as a means to embed citation metadata in webpages. More detail can be found at the OpenURL COinS website.
Saturday, March 11, 2006
Genealogical Embedded Citation Standard 0.1 (Strawman)
Thanks to Michael Nelson and Derek Maude for taking a first whack at what the structure for a genealogical embedded citation standard might be. The following structure is intended to be compatible with GEDCOM and the upcoming FamilySearch Family Tree. It could easily be implemented in XML or a microformat. There are some outstanding questions that Michael and Derek pose which follow this quick strawman proposal. Please review and share your thoughts through the comments link below or by e-mailing me (lawyerdc@ldschurch.org).
Looking for more information on Genealogical Embedded Citations? See the March 3rd article, Self-citing Internet Sources
Nested list of genealogical embedded citation elements
citation
url
film-number
sheet-number
page-number
frame-number
call-number
book-number
image-number
record-number
batch-number
serial-number
date-recorded
certainty
comment
source
url
title
author
abbreviation
publication-info
description
time-period
locality
language
film-number
call-number
batch-number
comment
repository
name
address
phone
email
url
comment
Just in case your browser doesn't like the way I've chosen to try and indent I've included a text description of the hierarchy at the bottom of the page.
Some questions to consider
1. Other formats have the ability to include the actual text. Is this necessary given the application?
2. Should there be a "provider" field for sources?
3. Should there be a "source-type" field for, say, stating the source is a census record?
4. Should this citation embedded in a page represent a citiation for that page or for the original record?
5. We included a description field and a comment field in the source. Is that necessary?
6. Should there be an "agency" field to include what organization originally created the record?
Text Description of Hierarchy
'Citation' is level 1 in the hierarchy. It contains the following level 2 elements: url, film-number, sheet-number, page-number, frame-number, call-number, book-number, image-number, record-number, batch-number, serial-number, date-recorded, certainty, comment, source.
The level 2 element 'source' contains the following level 3 elements: url, title, author, abbreviation, publication-info, description, time-period, locality, language, film-number, call-number, batch-number, comment, repository.
The level 3 element 'repository' contains the following level 4 elements: name, address, phone, email, url, comment.
Looking for more information on Genealogical Embedded Citations? See the March 3rd article, Self-citing Internet Sources
Nested list of genealogical embedded citation elements
citation
url
film-number
sheet-number
page-number
frame-number
call-number
book-number
image-number
record-number
batch-number
serial-number
date-recorded
certainty
comment
source
url
title
author
abbreviation
publication-info
description
time-period
locality
language
film-number
call-number
batch-number
comment
repository
name
address
phone
url
comment
Just in case your browser doesn't like the way I've chosen to try and indent I've included a text description of the hierarchy at the bottom of the page.
Some questions to consider
1. Other formats have the ability to include the actual text. Is this necessary given the application?
2. Should there be a "provider" field for sources?
3. Should there be a "source-type" field for, say, stating the source is a census record?
4. Should this citation embedded in a page represent a citiation for that page or for the original record?
5. We included a description field and a comment field in the source. Is that necessary?
6. Should there be an "agency" field to include what organization originally created the record?
Text Description of Hierarchy
'Citation' is level 1 in the hierarchy. It contains the following level 2 elements: url, film-number, sheet-number, page-number, frame-number, call-number, book-number, image-number, record-number, batch-number, serial-number, date-recorded, certainty, comment, source.
The level 2 element 'source' contains the following level 3 elements: url, title, author, abbreviation, publication-info, description, time-period, locality, language, film-number, call-number, batch-number, comment, repository.
The level 3 element 'repository' contains the following level 4 elements: name, address, phone, email, url, comment.
Tuesday, March 07, 2006
Engaging Ordinary People
Before diving further into technology and feature threads perhaps a foundation for the need to engage ordinary people in family history should be presented..
Why Take Genealogy to the Common Person?
Imagine a world where average people have a strong understanding of their heritage; the legacy and values of their ancestors; and interactions with others are in the context of their relationships – this guy sitting across the table from me is my 3rd cousin. Understanding our heritage and relationships brings more meaning and stability to life.
Interestingly, a high percentage of adults (estimates vary from 65-85%) have a desire to know more about their ancestors. There seems to be an innate desire to understand our heritage yet most people that go down this path are quickly overwhelmed by the obstacles. The end result is that while the majority of adults in the world are interested in the domain of family history at some level, very few are able to contribute productively to the effort of mapping the family of man. How might the world be different if the efforts of all the people interested in their roots could be harnessed and channeled to contribute more meaningfully toward the overall challenge of mapping our common family tree?
Finding and Adding an Ancestor to a Pedigree is REALLY Hard
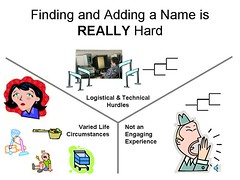
The reality of the world today is that for ordinary people finding and adding a name to their pedigree is very difficult. The challenges inherent to finding a name can be categorized into three areas: logistic and technical hurdles, varied life circumstances, and the reality that today’s tools don’t offer an engaging experience. These problem areas will be described in more detail in future posts. Solving these problems is a matter of answering the following questions:
Engaging Ordinary People
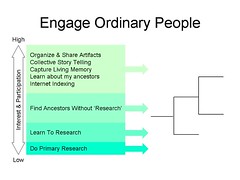
The diagram above represents a conceptual model for how to harness the efforts of ordinary people. It involves offering a broad range of activities that are inter-related. Each activity is meaningful in and of itself while contributing to the overall effort of a common family tree. Activities toward the top of the list are likely to have broader participation than those at the bottom of the list. As long as an activity adds to the overall effort of building our common heritage, it belongs on the list. The Web 2.0 philosophies and related technologies play very nicely into such a model.
Please offer your feedback on the ‘Engagement Model’ by adding comments to this post. Do you think this model has the potential to harness the combined efforts of millions?
Why Take Genealogy to the Common Person?
Imagine a world where average people have a strong understanding of their heritage; the legacy and values of their ancestors; and interactions with others are in the context of their relationships – this guy sitting across the table from me is my 3rd cousin. Understanding our heritage and relationships brings more meaning and stability to life.
Interestingly, a high percentage of adults (estimates vary from 65-85%) have a desire to know more about their ancestors. There seems to be an innate desire to understand our heritage yet most people that go down this path are quickly overwhelmed by the obstacles. The end result is that while the majority of adults in the world are interested in the domain of family history at some level, very few are able to contribute productively to the effort of mapping the family of man. How might the world be different if the efforts of all the people interested in their roots could be harnessed and channeled to contribute more meaningfully toward the overall challenge of mapping our common family tree?
Finding and Adding an Ancestor to a Pedigree is REALLY Hard
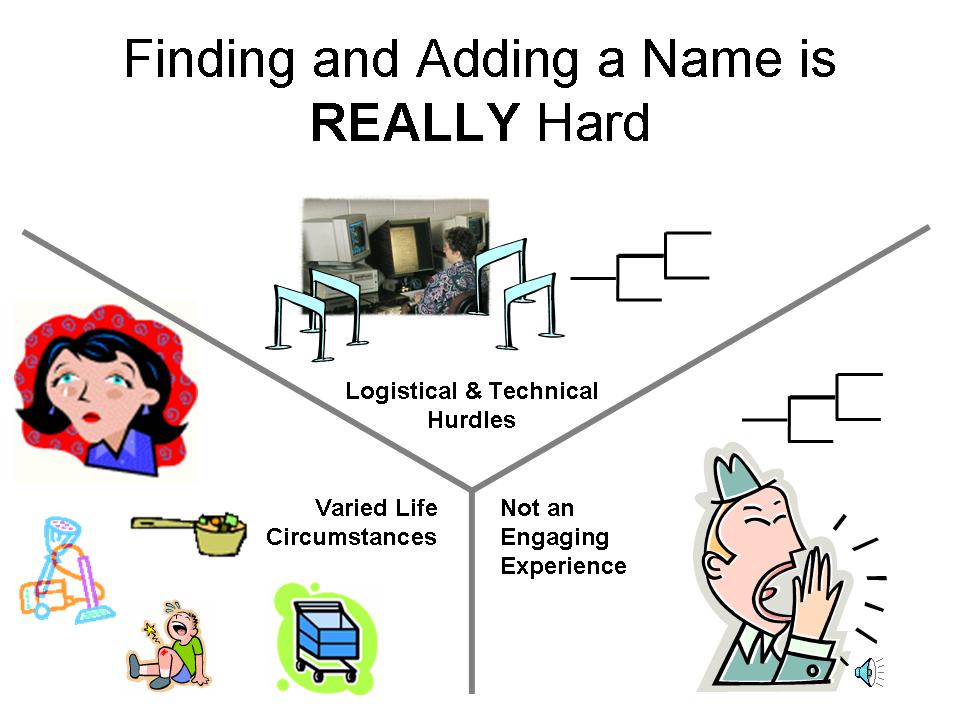
The reality of the world today is that for ordinary people finding and adding a name to their pedigree is very difficult. The challenges inherent to finding a name can be categorized into three areas: logistic and technical hurdles, varied life circumstances, and the reality that today’s tools don’t offer an engaging experience. These problem areas will be described in more detail in future posts. Solving these problems is a matter of answering the following questions:
- How do we remove logistic, technology, knowledge, skill, & economic barriers?
- How do we let ordinary people in a broad range of life circumstances contribute meaningfully?
- How do we deliver an experience that is inviting, interesting, and fulfilling?
Engaging Ordinary People
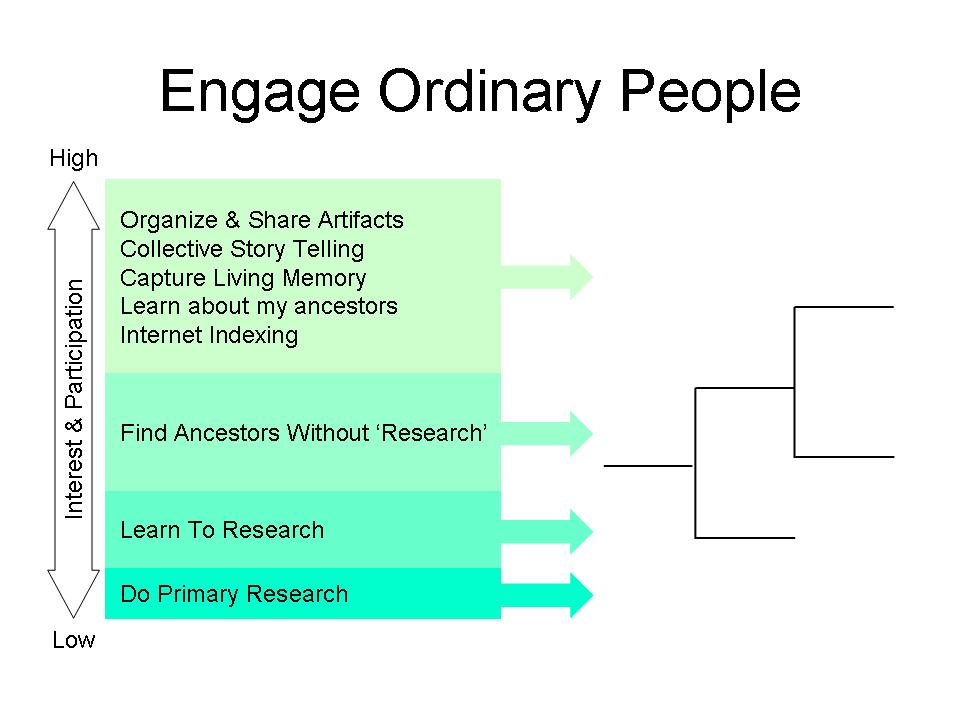
The diagram above represents a conceptual model for how to harness the efforts of ordinary people. It involves offering a broad range of activities that are inter-related. Each activity is meaningful in and of itself while contributing to the overall effort of a common family tree. Activities toward the top of the list are likely to have broader participation than those at the bottom of the list. As long as an activity adds to the overall effort of building our common heritage, it belongs on the list. The Web 2.0 philosophies and related technologies play very nicely into such a model.
Please offer your feedback on the ‘Engagement Model’ by adding comments to this post. Do you think this model has the potential to harness the combined efforts of millions?
Friday, March 03, 2006
Self-citing Internet Sources
Nearly every genealogical tool or service provider has at one time or other thought of how much better the world would be if there were a way to automatically cite the source of genealogical data on the Internet. Then they quickly get discouraged at the idea as they think of the level of industry cooperation that would be required to make it happen.
There are some isolated cases of self-citing sources. For example, PAF Insight Manager (OhanaSoftware) is a very popular tool among LDS genealogists. The tool has the ability to automatically cite sources of information obtained from the FamilySearch website. I'm sure there are other similar implementations of which I'm not currently aware. At the present time there does not seem to be a defacto standard for how to do this.
I don't think this is rocket science. We don't need some Automatic Citation Encapsulation (ACE) protocol. We simply need to agree upon a way to embed citation details into a web page. The citation detail doesn't neccessarily need to be viewable to the user. Any time an Internet-based source is cited, the tool or service can simply look at the citation details on the web page and
appropriately cite the source for the user. In fact, the embedded citation block could be as simple as the following:
<Embedded Citation Block>
Super Cool Online Internet Source Which Links Me to Adam
Published on Some Day
Found on Some Page
Random Text
</Embedded Citation Block>
There are a lot of extremely smart people that will look at the above example and immediately see that additional tags could be added to impose some type of taxonomy on the citation. Even if the embedded citation block was never more sophisticated than what is proposed above, it would be substantially better than the ad hoc citations of the masses that don't have degrees in library science.
The efficiency of an embedded citation block may be be questioned. After all, if an application is just trying to get the data in the citation block, why impose the overhead of serving up the rest of the web page? Wouldn't it be more efficient to have a service or simply a URL which only delivers the citation details without this overhead? There is some validity to this concern and the the approaches of embedding a citation block in the web page and offering a specific citation service or URL for obtaining just the citation details aren't mutually exclusive. I prefer the embedded citation block approach. It seems easier to implement. Anyone that can create a web page can create an embedded citation block.
So here's the rally cry. Let's get together and define an embedded citation block standard. Let's keep it as simple as possible to start and see if we can't get a few of the more popular online content providers and tool vendors to implement it. Send me your comments. FamilySearch can easily implement this approach into the system we are building to deliver digitized microfilm. How would you like to see this implemented?
There are some isolated cases of self-citing sources. For example, PAF Insight Manager (OhanaSoftware) is a very popular tool among LDS genealogists. The tool has the ability to automatically cite sources of information obtained from the FamilySearch website. I'm sure there are other similar implementations of which I'm not currently aware. At the present time there does not seem to be a defacto standard for how to do this.
I don't think this is rocket science. We don't need some Automatic Citation Encapsulation (ACE) protocol. We simply need to agree upon a way to embed citation details into a web page. The citation detail doesn't neccessarily need to be viewable to the user. Any time an Internet-based source is cited, the tool or service can simply look at the citation details on the web page and
appropriately cite the source for the user. In fact, the embedded citation block could be as simple as the following:
<Embedded Citation Block>
Super Cool Online Internet Source Which Links Me to Adam
Published on Some Day
Found on Some Page
Random Text
</Embedded Citation Block>
There are a lot of extremely smart people that will look at the above example and immediately see that additional tags could be added to impose some type of taxonomy on the citation. Even if the embedded citation block was never more sophisticated than what is proposed above, it would be substantially better than the ad hoc citations of the masses that don't have degrees in library science.
The efficiency of an embedded citation block may be be questioned. After all, if an application is just trying to get the data in the citation block, why impose the overhead of serving up the rest of the web page? Wouldn't it be more efficient to have a service or simply a URL which only delivers the citation details without this overhead? There is some validity to this concern and the the approaches of embedding a citation block in the web page and offering a specific citation service or URL for obtaining just the citation details aren't mutually exclusive. I prefer the embedded citation block approach. It seems easier to implement. Anyone that can create a web page can create an embedded citation block.
So here's the rally cry. Let's get together and define an embedded citation block standard. Let's keep it as simple as possible to start and see if we can't get a few of the more popular online content providers and tool vendors to implement it. Send me your comments. FamilySearch can easily implement this approach into the system we are building to deliver digitized microfilm. How would you like to see this implemented?
Subscribe to:
Comments (Atom)
