As family history applications become increasingly more collaborative in nature one of the primary issues to be considered has to do with sharing data. Using large brush strokes I can describe the trust model that users expect with regard to collaborating on their family history. Users tend to break their data down into three large chunks: my stuff, my shared stuff, and my published/public stuff. Notice that in all three cases they view it as my stuff. The difference is in who they are allowing to see their stuff. If the user were to encounter an application that doesn’t support this model they are likely to either abandon the tool or augment it. For example, if they used a tool that immediately published all of their work to the world, they would likely not use the tool. Instead, they would keep all of their stuff and their shared stuff someplace else until they were ready to publish. If they didn’t realize the tool was going to immediately publish and they used it, they would likely feel so burned by the experience that they would never come back.
The challenge to this is that fundamentally if people will share sooner they will make faster progress on their family history. They will more quickly find others working on the same problems that may already have the answer or can at least offer help. So how do we build a new generation of family history tools that support the user’s trust model but also encourage the user to share and publish sooner? Here are four ideas.
- Help the user always feel like it is their stuff. They own it. If they share it with you always allow them to get it back.
- Provide at least the three mental buckets: my stuff, my shared stuff, and my published/public stuff. This does not imply complex access control systems. The simplest form can be stuff that only I can see, stuff that people on my shared list can see, and stuff everyone can see. More and more I find complex grouping concepts in sharing to be too much for ordinary people. I really like the way Flickr.com has implemented this. Here is a snapshot of their access control.
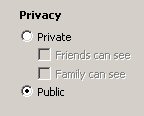
- Allow the flow of the program to encourage people to move their data from my stuff to my shared stuff to my published/public stuff as quickly as possible. Offer carrots to do it. For example, an application might look at my stuff and compare it to someone else’s stuff and then notify me that it looks like someone else is working on really similar stuff and ask if I’d like to contact that user and share some of my stuff.
- Allow the user to say “I think” or “Maybe” about their conclusions. This is an area of functionality that is tempting to make overly complex. You could build a whole feature set around analyzing the quality of evidence, a surety schema, etc., etc. Ordinary people are likely to be driven off by this. One simple way to implement this might be to have a flag or button associated with fields that indicate that the conclusion is really a hypothesis of sorts. This would allow the user to share their work in progress with others without losing that important piece of metadata “I think”. Systems could also be more cautious about how they propagate things marked with an “I think” flag.
In summary…
- If an application doesn’t support the user’s trust model they won’t use it.
- The user definitely has a trust model around collaboration.
- We need to support the user’s trust model while facilitating faster, more frequent collaboration.

11 comments:
Dan,
As usual, a very good post and so very, very true. It matches my sentiments exactly and explains why I have not placed my family history tree online yet. It still sits securely in my own laptop.
By the way, when is the Beta 2 verstion of Family Search going to be put out there?
Michael,
Thanks for the feedback. What would it take for you to feel like you could safely put your tree online?
As for when Beta 2 will be released, no man knoweth the day nor the hour
; )
Dan,
My comfort in trusting a particular website would be enhanced by a very clear and prominent policy from the website owner. I would want to make sure I understood their motivation for taking the time, effort, and cost in creating and maintaining the website (people just don't do things for free, ya' know!)
For example, I find the resources at Ancestry.com helpful because they took the time and expense to digitize some public records on their own. But they are definitely in it for the money and I don't trust them worth a darn. I would never use them for posting my family history.
Remember, the family history buff has a very large emotional investment in their work and it needs to be treated with respect and with care. If there is any hint of profit motivation by a geneaology website or company, it will immediately cause mistrust which will most likely never be regained.
There is another issue to remember. Once I give you my trust and understand your motivation for hosting my information, I need to be assured that you will make the greatest effort you can to keep it from falling into the hands of the profit mongers. Maybe there is a way of making sure they do not access the Family History site and directly copy the info into their own database. I am sure there are already companies out there thinking to hire Chinese and Indian labor just to input the names and dates off your site into their site.
I think you need to make sure the new Family History website allows for the end-user to remain in total control of who gets their information. This can be done using the model you suggest in the post. You can also clearly explain how saving the info in the granite mountain would allow all my hard work invested in my family history to be saved for future generations. Once a person completes a family history, it is rarely appreciated by the existing generation of aunts, uncles or cousins. It gets appreciated by those that come later on in 30 or 50 years.
You could find a way to allow the info to be used by other Family Search patrons in the case of death of the initial owner. For example, if I post all my info on the site and then die ten years later, the right to the info could be transferred to the church. It would still have to be protected from the profit mongers in some way but it could be made available to other true users of the website through some kind of verification system.
To conclude this long response, I think that the church has the ability to gain the trust of the Family Search users if we clearly communicate that our motivation is tied to our belief that the family is forever and our responsibility to keep a family record as God has commanded all the ancient saints. We won't sell, profit from, or collaborate with profit-seeking companies or websites.
Building that trust requires clear, upfront communication with the Family Search user.
Sorry for the verbose response but it is an important issue.
Excellent post. And I really like the ideas about simplifying the conclusions to a simple "maybe" and simplifying access rights. Simple is almost always better, especially when designing for the common person. Good thing I read this post before designing those parts of my project. :)
One other area where trust is helpful is undo. If a user can only undo one step (or even just a few), or if it's not predictable, then they won't feel as comfortable having that application safeguard their data. But if the user can undo any step, then they'll feel free to explore and try new things, and they won't have a nagging fear at the back of their head telling them to watch their step lest they mess up and lose it all.
Through careful use of existing family history tools, I could post my data online and trust that I can:
1) publish only that data that I wish to make public.
2) annotate my data to indicate which relationships are speculative.
3) remove my data, in part or in total, at anytime.
4) find matches for my data in other researchers' data.
So why don't I share my data online? I don't see the benefit to my research, and I feel there is actually a disincentive.
I published my family tree on WorldConnect once for several months. It did not generate contacts from other researchers. However, other researchers obviously found my data useful because my data quickly popped up in several other GEDCOMs published online. This brings me to the disincentive for sharing online: propagation of duplicate data. It is time-consuming--and frustrating--to follow-up on leads from online data only to discover that all the leads can be traced to a single, unsourced GEDCOM. I am doing my part to ameliorate this problem by not publishing my data online!
The carrot I need to publish data online is a truly collaborative environment. One where researchers can merge their data with other researchers' data to eliminate duplicate records. One where researchers can work toward a consensus on identities, relationships, and events. (Think Wikipedia's "Talk" (Discussion) pages.) One where researchers can mark records—theirs or others—that need "work". (Again, think Wikipedia, which uses article tags such as "cleanup" and "citations missing".)
I've read a little about the changes in FamilySearch v2, and I am crossing my fingers that it will provide the collaborative environment looking for.
It is becoming clear that there are multiple view points of what it means to publish genealogical data. I wasn't very clear about my own bias on this when I wrote my original post. What I truly believe is that published genealogical data should be equivalent to public genealogical data, as in public domain.
I strongly agree with Mark and Regina in the view that public domain genealogical data needs to have a collaborative infrastructure supporting it. This is one of the philosophies behind the New FamilySearch. I believe the new FamilySearch will provide the basic infrastructure to begin facilitating broad cross-family collaboration that will enhance in functionality over time.
Dear Mark,
From your comments, I know that you do not have as much of a problem with the "profit mongers" as I do. And I understand your legal definitions of "creative expression" and "sweat of the brow".
However, I feel that by casually dismissing the fear that my family history work can be used by for-profit corporations or services without my permission (including professional genealogists who do not complete their own research but merely rely upon non-sourced family trees listed on the web) you are not fully grasping the emotions involved in this work.
A family history (no matter how public the records) is a sacred and personal thing that is to be used to keep a record of the connections and relationships associated with my life. Even those people that are not LDS have the same strong emotions surrounding this issue (I am a convert so I know both sides).
Therefore, any attempt to justify the profit aspect or to minimize the emotional concerns is not going to get us to our goal of better collaboration. I think that the trust issue that Dan raises is extremely important.
Dan,
Thank you for clarifying. However, if Beta 2 will take family history information and make it into a public domain work, I feel that you will still have a very difficult time in getting people to post their work.
I may be on a lonely island when it comes to my opinion but I would suggest also giving consideration to other types of collaboration tools instead of just "publishing". These may include message boards or some sort of "telephone directory" sorted by countries and counties where you can list your contact info for others to see. Perhaps it can be in the form of a world map where you can click down to the various regions and see who is also interested in that area.
Michael,
The New FamilySearch is not a public domain system. I hope that it will evolve toward that but there are many things which need to be in place to support such a model which don't exist yet. That would be an interesting post at sometime.
The New FamilySearch does make an effort to get everyone playing off of the same data set. It could be characterized as a multi-user pedigree. It allows people to express their conclusions about their ancestry and see others conclusions and where they differ. The hope is that as people see each others conclusions they will converge on the truth. There will of course always be those that persist in a minority view of their ancestry.
I don't want to get into too much detail on the functionality of the new system as I'm not an official spokesperson. I do believe it is a huge step in the right direction. As expressed in this thread, there is a very fine balance between keeping the user's trust and fostering collaboration.
Sorry, not sure as my first attempt got though - trying again.
Micheal,
Like others, I don't really have a problem with posting to a for profit site. I have only limited experience with Ancestry.com, but from what I understand, their profit comes from subscriptions. They aren't likely to do anything to upset their subscribers. As such, I'm probably more likely to trust them then some others. I'm unlikely to trust anyone whose business model I can't understand - because it probably means there's something I don't know.
However, my main point was that while you and I might trust the Church's website, non-members may not feel the same way. In fact the may be some just as adamant about not submitting anything to "the Mormons" as you have about for-profit sites.
In practical terms, I'm not sure what can be done about the plagiarizing profit-mongers. I think most of them flourish when the original free source is too obscure to the average user. So the better promoted the site, then less likely anyone will get a profit from taking information from it.
Case in point. Someone came onto an automotive forum with an informative article and said in the end "if you like this, contact me at...". Funny thing is that article contained a number of links to Wikipedia (you know how key terms frequently link to other articles?) A quick check - sure enough. "His" article was little more then a cut and paste from Wikipedia. Did he gain anything from his plagiarism? Probably not as he was ratted out rather quickly.
Now, you do raise a valid point. People do tend to have a rather heavy emotional investment in their work. They consider it "their" genealogy - their property. While I have little to go on, I suspect the compiled genealogies to date amount to a small fraction of what needs to be done. Small enough that we can ignore everyone who wants to hold and hide "their" information. What's needed is to build a collaborative system where people work together to build "our" genealogy. I think people who have collaborated semi-publicly are much more willing to share "our" work. And what happens to those who have horded "their" information when they see others duplicating and publishing the work? Probably about like those who tried to hoard the manna from one day to the next. So my suggestion to Dan is to concentrate on collaboration and the rest will take care of itself in time. Those who want to get on board will and those that won't will probably find themselves left behind.
Another aspect to "trust" - to have a usable export and not hold user's data as "hostage" to discourage changing to another program.
Post a Comment